一、背景
随着AI技术的进一步发展,常见的如:微调等手段在前期的数据准备上已经有成熟的方案,但是对于企业数据的快速增长状态依然无法满足。> 也就是大多数的AI应用都卡在了资料库检索与模型记忆这两个方向,而RAG的出现,从侧面部分的解决了这个问题,当然:对于个人知识库来说,现在又更好的方案,一切皆Markdown格式化文本(注意:这里有个前提是个人小数据量开发者)。> 当然,作为RAG技术来说,数据检索可以有多种多样,比如:传统结构化数据(这是最佳的情况)。但我们在生产过程中产生的数据大多数是非结构化数据,如:一段长文本聊天、一篇文档、一张照片、一段音频,甚至一段视频文件。> 这时候通过向量数据检索的方案也就应运而生了,而通过支持向量检索的数据库也就应运而生了。
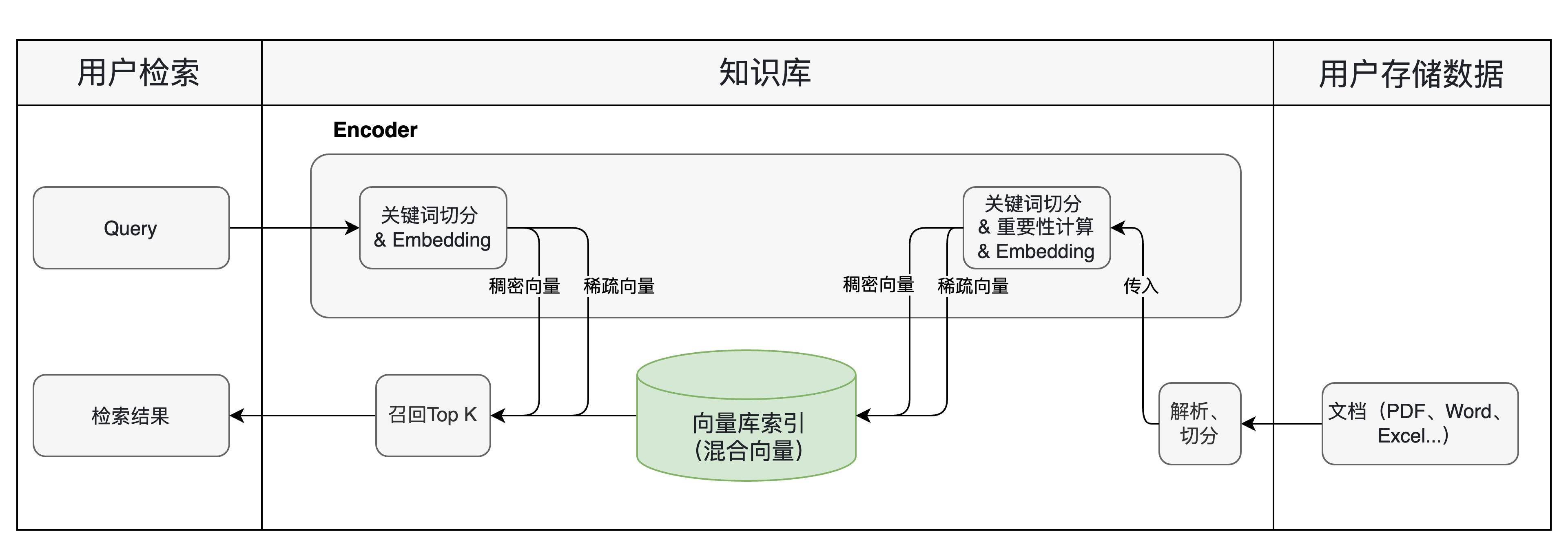
二、流程图
三、常见的向量数据库(简要,后面会专门针对常见的向量库出几篇文章以及示例)
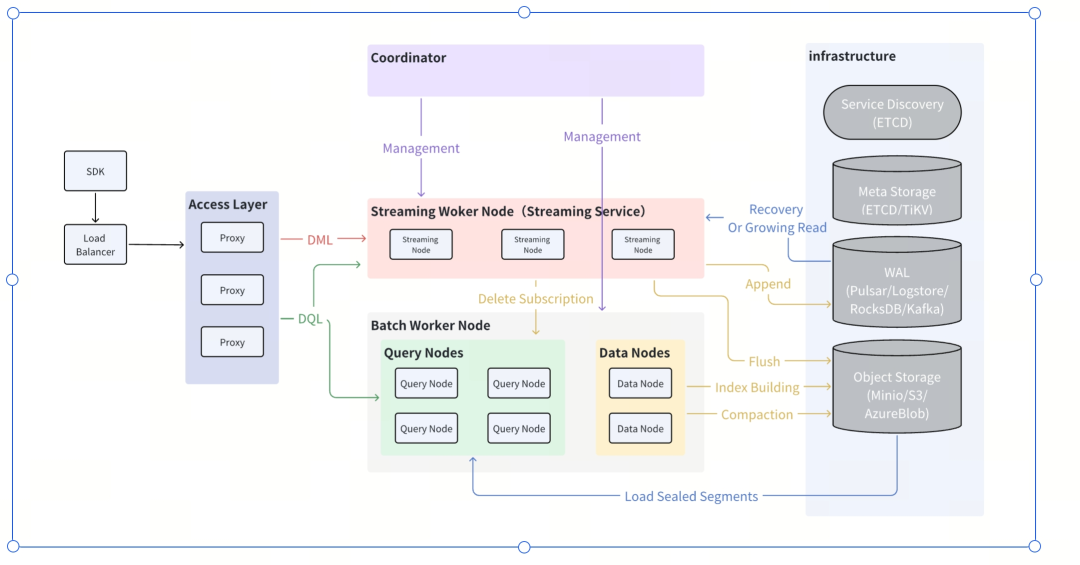
3.1 Milvus
开源云原生向量数据库,高可用,高性能,易拓展,支持混合索引,采用存算分离的极致,计算节点可以横向扩展,用于海量数据检索。
-
架构
-
简单示例:
import io.milvus.client.MilvusClient; import io.milvus.param.*; import io.milvus.param.collection.SearchParam; import io.milvus.grpc.SearchResults; import io.milvus.grpc.SearchResultData; // 初始化客户端 MilvusClient client = new MilvusClient(ConnectParam.newBuilder() .withHost("localhost") .withPort(19530) .build()); // 构建搜索请求 SearchParam searchParam = SearchParam.newBuilder() .withCollectionName("docs") .withVectorFieldName("embedding") .withVectors(Collections.singletonList(queryVector)) .withMetricType(MetricType.COSINE) .withTopK(10) .withExpr("category == 'AI'") // 标量过滤 .build(); SearchResults results = client.search(searchParam); List<SearchResultData> resultData = results.getResults().getFieldsDataList(); -
优点:
- 分布式存储,存算分离,计算节点可以横向扩展,存储节点使用云原生对象存储
- 三级存储架构:内存层、本地缓存和对象存储
- 支持索引类型丰富:HNSW, IVF, DiskANN以及CAGRA(GPU加速)
- 支持混合搜索:向量、全文、标量过滤
-
缺点:
- 部署复杂
- 太过庞大: 对中小型数据规模来说,过于庞大就带来更多的维护问题以及成本问题
-
适用场景:
- 大规模图片、视频检索
- 大型平台推荐系统
- 大型企业RAG应用
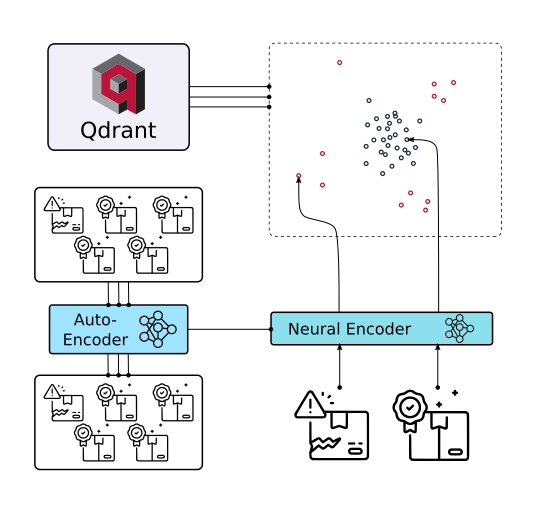
3.1 Qdrant:我一只在使用的向量库
部署简单,支持常见的现代化索引,Rust带来的内存安全,性能不错,支持混合检索
-
架构图
-
先说优点:
- RUST开发:内存安全,性能不错
- 可组合设计:精确控制检索环节
- 支持稠密与稀疏向量混合使用
- 部署极为简单,占用资源很少,极适宜中小型数据规模使用
-
缺点:
- 不适宜大规模数据使用
- 非云原生
-
场景
- 中小型数据量,延迟低要求
- 个人知识库或者中小型企业知识库
- 边缘设备部署
- 我自己用着很舒服
3.3 pgvector
原postgresql的向量扩展库,依托于postgresql的生态支持,比如:扩展、事物支持等
这个库其实没什么说的,作为传统关系型数据库,在关系库上加入了对向量检索的支持,目前支持的索引有:IVFlat, HNSW如果有大量的结构化数据,并且对事物有较高的一致性要求,非机构化数据并不大,或者不需要大量的非结构化数据场景,这个库就是不二选择。
题外话:物理世界要求的是准确性,而不是非准确性,向量库虽然能解决非结构化数据的问题,但是结构化数据依然是对准确的物理世界可靠度量工具之一。对于大多数工业、数字、金融和政务行业来说,准确性依然是一个绕不过的门槛,AI如果要真正落地就已经要切近物理的真实世界,这个世界是非泛化的。
所以,pgvector作为关系型数据库,依然是企业场景下可选的工具之一
四、常见的向量库索引
Flat:准确索引
这个检索算法没什么可说的,要求准确性,对速度没太高要求,做Embedding基线测试都可以用
-
使用场景:
- 数据量不大的精确索引
- ANN评测极限
-
特点:
- 不做近似,全量比较
- 最准确
- 最慢
-
代码:
"""FAISS flat index 原生 API 使用示例。 直接调用 faiss 库,演示: 1. IndexFlatL2 / IndexFlatIP 的创建与搜索 2. IndexIDMap2 绑定自定义 ID 3. 向量增删、保存加载 4. 与 numpy 手写余弦相似度的结果对比 """ from __future__ import annotations import logging import faiss import numpy as np logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) def cosine_similarity(a: np.ndarray, b: np.ndarray) -> float: dot = float(np.dot(a, b)) norm_a = float(np.linalg.norm(a)) norm_b = float(np.linalg.norm(b)) if norm_a == 0.0 or norm_b == 0.0: return 0.0 return dot / (norm_a * norm_b) def brute_force_search( xb: np.ndarray, query: np.ndarray, top_k: int = 5 ) -> list[tuple[int, float]]: scored = [] for idx, vec in enumerate(xb): score = cosine_similarity(query, vec) scored.append((score, idx)) scored.sort(key=lambda x: x[0], reverse=True) return [(idx, score) for score, idx in scored[:top_k]] def main() -> None: dim = 128 n_vectors = 100 top_k = 5 # 生成随机向量(已归一化,方便与 Inner Product 对比) xb = np.random.rand(n_vectors, dim).astype("float32") xb = xb / np.linalg.norm(xb, axis=1, keepdims=True) # 自定义 ID:0 ~ 99 映射到 1000 ~ 1099 ids = np.arange(1000, 1000 + n_vectors, dtype="int64") query = np.random.rand(dim).astype("float32") query = query / np.linalg.norm(query) # =================== 1. IndexFlatIP(内积 = 余弦相似度,因已归一化) =================== logger.info("=== 1. IndexFlatIP(内积) ===") index_ip = faiss.IndexFlatIP(dim) index_ip_with_ids = faiss.IndexIDMap2(index_ip) index_ip_with_ids.add_with_ids(xb, ids) logger.info("总向量数: %d", index_ip_with_ids.ntotal) xq = query.reshape(1, -1) distances, indices = index_ip_with_ids.search(xq, top_k) for dist, idx in zip(distances[0], indices[0]): logger.info(" faiss_id=%d | inner_product=%.4f", idx, dist) # =================== 2. IndexFlatL2(欧氏距离) =================== logger.info("=== 2. IndexFlatL2(欧氏距离) ===") index_l2 = faiss.IndexFlatL2(dim) index_l2_with_ids = faiss.IndexIDMap2(index_l2) index_l2_with_ids.add_with_ids(xb, ids) distances_l2, indices_l2 = index_l2_with_ids.search(xq, top_k) for dist, idx in zip(distances_l2[0], indices_l2[0]): logger.info(" faiss_id=%d | l2_distance=%.4f", idx, dist) # =================== 3. 与 numpy 手写余弦相似度对比 =================== logger.info("=== 3. numpy 手写余弦相似度(Brute-Force) ===") brute_results = brute_force_search(xb, query, top_k) for idx, score in brute_results: logger.info(" idx=%d | cosine=%.4f | faiss_id=%d", idx, score, ids[idx]) # =================== 4. 删除向量 =================== logger.info("=== 4. 删除向量 id=1000 ===") index_ip_with_ids.remove_ids(np.array([1000], dtype="int64")) logger.info("删除后总向量数: %d", index_ip_with_ids.ntotal) distances_after, indices_after = index_ip_with_ids.search(xq, top_k) for dist, idx in zip(distances_after[0], indices_after[0]): logger.info(" faiss_id=%d | inner_product=%.4f", idx, dist) # =================== 5. 保存 / 加载索引 =================== logger.info("=== 5. 保存 / 加载索引 ===") faiss.write_index(index_ip_with_ids, "/tmp/demo_flat_ip.index") loaded_index = faiss.read_index("/tmp/demo_flat_ip.index") logger.info("加载后总向量数: %d", loaded_index.ntotal) distances_loaded, indices_loaded = loaded_index.search(xq, top_k) for dist, idx in zip(distances_loaded[0], indices_loaded[0]): logger.info(" faiss_id=%d | inner_product=%.4f", idx, dist) # =================== 6. 批量查询 =================== logger.info("=== 6. 批量查询(3 条 query) ===") xq_batch = np.random.rand(3, dim).astype("float32") xq_batch = xq_batch / np.linalg.norm(xq_batch, axis=1, keepdims=True) distances_batch, indices_batch = loaded_index.search(xq_batch, top_k) for i in range(3): logger.info(" Query %d:", i) for dist, idx in zip(distances_batch[i], indices_batch[i]): logger.info(" faiss_id=%d | inner_product=%.4f", idx, dist) if __name__ == "__main__": main()
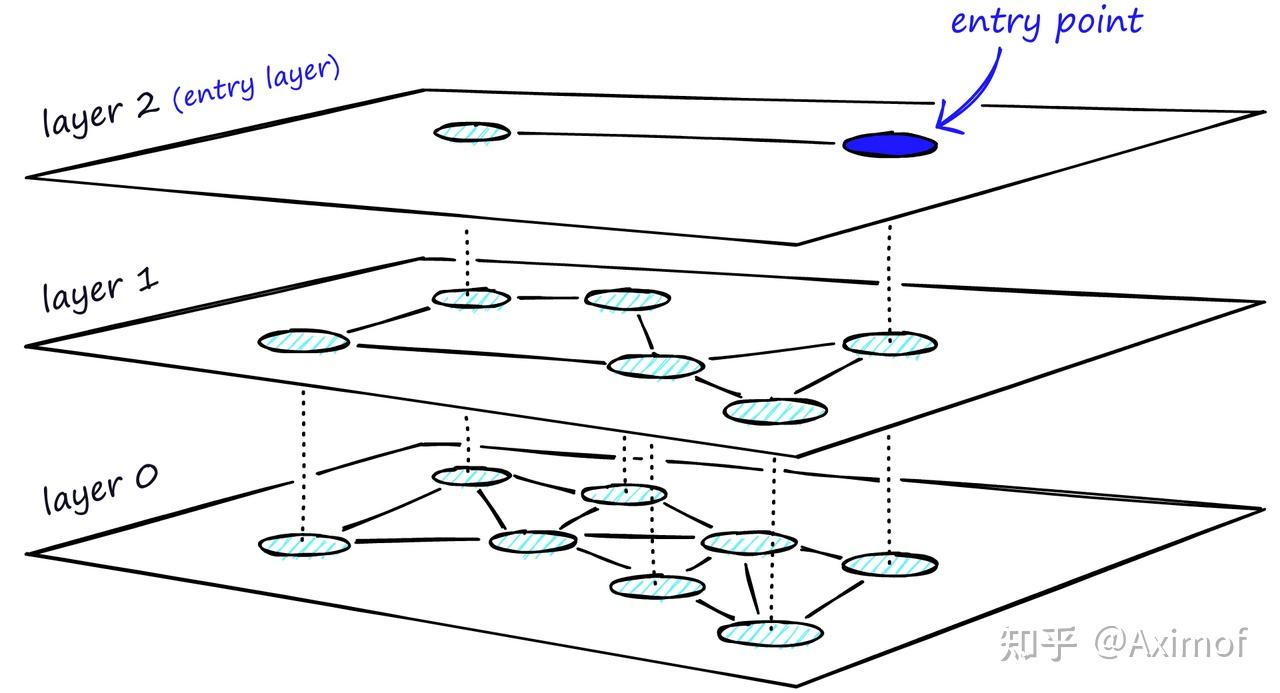
HNSW:Hierarchical Navigable Small Worlds
也是常见的索引类型,ANN算法中图的一种,结构也很好理解
-
场景:
- 大规模语义检索,内存规模较大(图带来的问题)
- 高recall要求
- 查询速度要快
-
特点:
- 图索引
- 查询快
- recall高
- 内存占用相对较高
-
核心参数
- m:每个节点最多多少个编,m越大,图越密,内存占用越高
- efConstruction:建图时搜索多宽,建图越慢,质量更高
- efSearch:查询时搜索多宽,查询更准确,但速度更慢
-
代码实现:
"""FAISS HNSW (Hierarchical Navigable Small World) 原生 API 使用示例。 直接调用 faiss 库,演示: 1. IndexHNSWFlat 的创建与搜索 2. efConstruction / efSearch 参数调优 3. 与 IndexFlatL2 的召回率与速度对比 4. 保存 / 加载索引 """ from __future__ import annotations import logging import time import faiss import numpy as np logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) def recall_at_k( ground_truth: np.ndarray, approx_results: np.ndarray, k: int ) -> float: """计算召回率:approx_results 中有多少命中 ground_truth 前 k 个。""" correct = 0 total = 0 for gt_row, app_row in zip(ground_truth, approx_results): gt_set = set(gt_row[:k]) app_set = set(app_row[:k]) correct += len(gt_set & app_set) total += k return correct / total def main() -> None: dim = 128 n_vectors = 10_000 n_queries = 100 top_k = 10 hnsw_m = 32 # 生成随机向量(未归一化,使用 L2 距离) logger.info("生成数据: %d 条向量, dim=%d", n_vectors, dim) xb = np.random.rand(n_vectors, dim).astype("float32") xq = np.random.rand(n_queries, dim).astype("float32") # =================== 1. 精确搜索(Flat L2)作为 ground truth =================== logger.info("=== 1. IndexFlatL2(精确搜索,作为 Ground Truth) ===") index_flat = faiss.IndexFlatL2(dim) index_flat.add(xb) t0 = time.perf_counter() distances_flat, indices_flat = index_flat.search(xq, top_k) flat_time = time.perf_counter() - t0 logger.info("FlatL2 搜索耗时: %.4f s", flat_time) # =================== 2. HNSW Flat 索引 =================== logger.info("=== 2. IndexHNSWFlat(近似搜索) ===") index_hnsw = faiss.IndexHNSWFlat(dim, hnsw_m) # efConstruction: 建图时的搜索宽度,越大图质量越高,建图越慢 index_hnsw.hnsw.efConstruction = 200 index_hnsw.add(xb) logger.info("HNSW 图构建完成,总向量数: %d", index_hnsw.ntotal) # efSearch: 查询时的搜索宽度,越大召回率越高,查询越慢 for ef in [16, 64, 200]: index_hnsw.hnsw.efSearch = ef t0 = time.perf_counter() distances_hnsw, indices_hnsw = index_hnsw.search(xq, top_k) hnsw_time = time.perf_counter() - t0 recall = recall_at_k(indices_flat, indices_hnsw, top_k) logger.info( " efSearch=%3d | 耗时=%.4f s | 召回率@10=%.2f%% | 加速比=%.1fx", ef, hnsw_time, recall * 100, flat_time / hnsw_time, ) # =================== 3. HNSW + IDMap(支持自定义 ID) =================== logger.info("=== 3. IndexHNSWFlat + IDMap2(自定义 ID) ===") base_hnsw = faiss.IndexHNSWFlat(dim, hnsw_m) base_hnsw.hnsw.efConstruction = 200 index_hnsw_id = faiss.IndexIDMap2(base_hnsw) ids = np.arange(1000, 1000 + n_vectors, dtype="int64") index_hnsw_id.add_with_ids(xb, ids) # IndexIDMap2 包装后需 downcast 才能访问底层 HNSW 属性 hnsw_core = faiss.downcast_index(index_hnsw_id.index) hnsw_core.hnsw.efSearch = 64 distances_id, indices_id = index_hnsw_id.search(xq[:5], top_k) for i in range(5): logger.info(" Query %d:", i) for dist, idx in zip(distances_id[i], indices_id[i]): logger.info(" faiss_id=%d | l2_distance=%.4f", idx, dist) # =================== 4. 保存 / 加载 HNSW 索引 =================== logger.info("=== 4. 保存 / 加载 HNSW 索引 ===") faiss.write_index(index_hnsw, "/tmp/demo_hnsw.index") loaded_hnsw = faiss.read_index("/tmp/demo_hnsw.index") logger.info("加载后总向量数: %d", loaded_hnsw.ntotal) loaded_hnsw.hnsw.efSearch = 64 distances_loaded, indices_loaded = loaded_hnsw.search(xq[:3], top_k) for i in range(3): logger.info(" Query %d:", i) for dist, idx in zip(distances_loaded[i], indices_loaded[i]): logger.info(" idx=%d | l2_distance=%.4f", idx, dist) # =================== 5. 不同 M 参数对比 =================== logger.info("=== 5. 不同 M 参数(邻居数)对比 ===") for m in [8, 16, 32]: idx_hnsw = faiss.IndexHNSWFlat(dim, m) idx_hnsw.hnsw.efConstruction = 200 idx_hnsw.add(xb) idx_hnsw.hnsw.efSearch = 64 t0 = time.perf_counter() _, indices_m = idx_hnsw.search(xq, top_k) t_m = time.perf_counter() - t0 recall_m = recall_at_k(indices_flat, indices_m, top_k) logger.info( " M=%2d | 召回率@10=%.2f%% | 搜索耗时=%.4f s", m, recall_m * 100, t_m, ) if __name__ == "__main__": main()
IVF_FLAT:分桶后精确查询
相比较FLAT查询,IVF_FLAT引入了分桶查询,也就是先聚(K-Means)类再查询,相较于FLAT查询:
- 查询速度更快
- 近似查询
- 参数对查询结果影响比较大
-
参数:
- nlist:桶的数量,数量越多,查询结果越精确,速度越慢
- nprobe:查询桶数量,查询桶越多,越精确,速度越慢
-
场景:
- 数据量大于HNSW的极限
- 不想引入压缩误差,但是可接受一定的相似性查询
-
代码
"""FAISS IVF-Flat (Inverted File + Flat) 原生 API 使用示例。 直接调用 faiss 库,演示: 1. IndexIVFFlat 的创建、训练与搜索 2. nlist(聚类中心数)与 nprobe(查询时扫描的聚类数)调优 3. 与 IndexFlatL2 的召回率与速度对比 4. 保存 / 加载索引 """ from __future__ import annotations import logging import time import faiss import numpy as np logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) def recall_at_k( ground_truth: np.ndarray, approx_results: np.ndarray, k: int ) -> float: """计算召回率:approx_results 中有多少命中 ground_truth 前 k 个。""" correct = 0 total = 0 for gt_row, app_row in zip(ground_truth, approx_results): gt_set = set(gt_row[:k]) app_set = set(app_row[:k]) correct += len(gt_set & app_set) total += k return correct / total def main() -> None: dim = 128 n_vectors = 50_000 n_queries = 200 top_k = 10 nlist = 100 # 生成随机向量 logger.info("生成数据: %d 条向量, dim=%d", n_vectors, dim) xb = np.random.rand(n_vectors, dim).astype("float32") xq = np.random.rand(n_queries, dim).astype("float32") # =================== 1. 精确搜索(Flat L2)作为 ground truth =================== logger.info("=== 1. IndexFlatL2(精确搜索,作为 Ground Truth) ===") index_flat = faiss.IndexFlatL2(dim) index_flat.add(xb) t0 = time.perf_counter() distances_flat, indices_flat = index_flat.search(xq, top_k) flat_time = time.perf_counter() - t0 logger.info("FlatL2 搜索耗时: %.4f s", flat_time) # =================== 2. IVF-Flat 索引 =================== logger.info("=== 2. IndexIVFFlat(倒排 + Flat 精确搜索) ===") quantizer = faiss.IndexFlatL2(dim) index_ivf = faiss.IndexIVFFlat(quantizer, dim, nlist) # IVF 索引需要先训练(对 xb 做 k-means 聚类) logger.info("训练 IVF 索引 (nlist=%d)...", nlist) index_ivf.train(xb) index_ivf.add(xb) logger.info("IVF 索引构建完成,总向量数: %d, 是否训练: %s", index_ivf.ntotal, index_ivf.is_trained) # nprobe: 查询时扫描的聚类中心数,越大召回率越高,查询越慢 for nprobe in [1, 5, 10, 50, 100]: index_ivf.nprobe = nprobe t0 = time.perf_counter() distances_ivf, indices_ivf = index_ivf.search(xq, top_k) ivf_time = time.perf_counter() - t0 recall = recall_at_k(indices_flat, indices_ivf, top_k) logger.info( " nprobe=%3d | 耗时=%.4f s | 召回率@10=%.2f%% | 加速比=%.1fx", nprobe, ivf_time, recall * 100, flat_time / ivf_time, ) # =================== 3. IVF-Flat + IDMap(支持自定义 ID) =================== logger.info("=== 3. IndexIVFFlat + IDMap2(自定义 ID) ===") quantizer_id = faiss.IndexFlatL2(dim) base_ivf = faiss.IndexIVFFlat(quantizer_id, dim, nlist) base_ivf.train(xb) index_ivf_id = faiss.IndexIDMap2(base_ivf) ids = np.arange(1000, 1000 + n_vectors, dtype="int64") index_ivf_id.add_with_ids(xb, ids) # 通过 downcast 访问底层 IVF 的 nprobe faiss.downcast_index(index_ivf_id.index).nprobe = 10 distances_id, indices_id = index_ivf_id.search(xq[:5], top_k) for i in range(5): logger.info(" Query %d:", i) for dist, idx in zip(distances_id[i], indices_id[i]): logger.info(" faiss_id=%d | l2_distance=%.4f", idx, dist) # =================== 4. 保存 / 加载 IVF 索引 =================== logger.info("=== 4. 保存 / 加载 IVF 索引 ===") faiss.write_index(index_ivf, "/tmp/demo_ivf_flat.index") loaded_ivf = faiss.read_index("/tmp/demo_ivf_flat.index") logger.info("加载后总向量数: %d, 是否训练: %s", loaded_ivf.ntotal, loaded_ivf.is_trained) loaded_ivf.nprobe = 10 distances_loaded, indices_loaded = loaded_ivf.search(xq[:3], top_k) for i in range(3): logger.info(" Query %d:", i) for dist, idx in zip(distances_loaded[i], indices_loaded[i]): logger.info(" idx=%d | l2_distance=%.4f", idx, dist) # =================== 5. 不同 nlist 参数对比 =================== logger.info("=== 5. 不同 nlist(聚类中心数)对比 ===") for nl in [10, 50, 100, 200]: q = faiss.IndexFlatL2(dim) idx_ivf = faiss.IndexIVFFlat(q, dim, nl) idx_ivf.train(xb) idx_ivf.add(xb) idx_ivf.nprobe = 10 t0 = time.perf_counter() _, indices_nl = idx_ivf.search(xq, top_k) t_nl = time.perf_counter() - t0 recall_nl = recall_at_k(indices_flat, indices_nl, top_k) logger.info( " nlist=%3d | 召回率@10=%.2f%% | 搜索耗时=%.4f s", nl, recall_nl * 100, t_nl, ) if __name__ == "__main__": main()
IVF_PQ:分桶压缩
相比较IVF_FLAT来说:PQ对分桶的数据进行了压缩
-
场景:
- 数据量很大
- 内存压力
- 可以接受精度损失
- 工业中比较常见:工业数据一般比较庞大,而且多数为时序数据,如某密度传感器等
-
核心参数:
- nlist:桶数
- m:向量PG段数
- nbits:每段编码多少bit
- nprobe:查询桶数
-
代码示例
"""FAISS IVF-PQ (Inverted File + Product Quantization) 原生 API 使用示例。 直接调用 faiss 库,演示: 1. IndexIVFPQ 的创建、训练与搜索 2. nprobe(查询聚类数)与 PQ 参数(m, nbits)调优 3. 与 IndexFlatL2 的召回率与速度对比 4. 保存 / 加载索引 """ from __future__ import annotations import logging import time import faiss import numpy as np logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) def recall_at_k(ground_truth: np.ndarray, approx_results: np.ndarray, k: int) -> float: """计算召回率:approx_results 中有多少命中 ground_truth 前 k 个。""" correct = 0 total = 0 for gt_row, app_row in zip(ground_truth, approx_results): gt_set = set(gt_row[:k]) app_set = set(app_row[:k]) correct += len(gt_set & app_set) total += k return correct / total def main() -> None: dim = 128 n_vectors = 50_000 n_queries = 200 top_k = 10 nlist = 100 m = 16 # PQ 子空间数,必须整除 dim (128) nbits = 8 # 每个子空间 8 bits => 256 个聚类中心 # 生成随机向量 logger.info("生成数据: %d 条向量, dim=%d", n_vectors, dim) xb = np.random.rand(n_vectors, dim).astype("float32") xq = np.random.rand(n_queries, dim).astype("float32") # =================== 1. 精确搜索(Flat L2)作为 ground truth =================== logger.info("=== 1. IndexFlatL2(精确搜索,作为 Ground Truth) ===") index_flat = faiss.IndexFlatL2(dim) index_flat.add(xb) t0 = time.perf_counter() distances_flat, indices_flat = index_flat.search(xq, top_k) flat_time = time.perf_counter() - t0 logger.info("FlatL2 搜索耗时: %.4f s", flat_time) # =================== 2. IVF-PQ 索引 =================== logger.info("=== 2. IndexIVFPQ(倒排 + 乘积量化) ===") quantizer = faiss.IndexFlatL2(dim) index_ivfpq = faiss.IndexIVFPQ(quantizer, dim, nlist, m, nbits) # IVF-PQ 索引需要先训练(k-means + PQ 码本学习) logger.info("训练 IVF-PQ 索引 (nlist=%d, m=%d, nbits=%d)...", nlist, m, nbits) index_ivfpq.train(xb) index_ivfpq.add(xb) logger.info( "IVF-PQ 索引构建完成,总向量数: %d, 是否训练: %s", index_ivfpq.ntotal, index_ivfpq.is_trained, ) # nprobe: 查询时扫描的聚类中心数,越大召回率越高,查询越慢 for nprobe in [1, 5, 10, 50, 100]: index_ivfpq.nprobe = nprobe t0 = time.perf_counter() distances_ivfpq, indices_ivfpq = index_ivfpq.search(xq, top_k) ivfpq_time = time.perf_counter() - t0 recall = recall_at_k(indices_flat, indices_ivfpq, top_k) logger.info( " nprobe=%3d | 耗时=%.4f s | 召回率@10=%.2f%% | 加速比=%.1fx", nprobe, ivfpq_time, recall * 100, flat_time / ivfpq_time, ) # =================== 3. IVF-PQ + IDMap(支持自定义 ID) =================== logger.info("=== 3. IndexIVFPQ + IDMap2(自定义 ID) ===") quantizer_id = faiss.IndexFlatL2(dim) base_ivfpq = faiss.IndexIVFPQ(quantizer_id, dim, nlist, m, nbits) base_ivfpq.train(xb) index_ivfpq_id = faiss.IndexIDMap2(base_ivfpq) ids = np.arange(1000, 1000 + n_vectors, dtype="int64") index_ivfpq_id.add_with_ids(xb, ids) # 通过 downcast 访问底层 IVF 的 nprobe faiss.downcast_index(index_ivfpq_id.index).nprobe = 10 distances_id, indices_id = index_ivfpq_id.search(xq[:5], top_k) for i in range(5): logger.info(" Query %d:", i) for dist, idx in zip(distances_id[i], indices_id[i]): logger.info(" faiss_id=%d | l2_distance=%.4f", idx, dist) # =================== 4. 保存 / 加载 IVF-PQ 索引 =================== logger.info("=== 4. 保存 / 加载 IVF-PQ 索引 ===") faiss.write_index(index_ivfpq, "/tmp/demo_ivfpq.index") loaded_ivfpq = faiss.read_index("/tmp/demo_ivfpq.index") logger.info( "加载后总向量数: %d, 是否训练: %s", loaded_ivfpq.ntotal, loaded_ivfpq.is_trained, ) loaded_ivfpq.nprobe = 10 distances_loaded, indices_loaded = loaded_ivfpq.search(xq[:3], top_k) for i in range(3): logger.info(" Query %d:", i) for dist, idx in zip(distances_loaded[i], indices_loaded[i]): logger.info(" idx=%d | l2_distance=%.4f", idx, dist) # =================== 5. 不同 m(子空间数)对比 =================== logger.info("=== 5. 不同 m(PQ 子空间数)对比 ===") for m_test in [8, 16, 32]: q = faiss.IndexFlatL2(dim) idx_ivfpq = faiss.IndexIVFPQ(q, dim, nlist, m_test, nbits) idx_ivfpq.train(xb) idx_ivfpq.add(xb) idx_ivfpq.nprobe = 10 t0 = time.perf_counter() _, indices_m = idx_ivfpq.search(xq, top_k) t_m = time.perf_counter() - t0 recall_m = recall_at_k(indices_flat, indices_m, top_k) logger.info( " m=%2d | 召回率@10=%.2f%% | 搜索耗时=%.4f s | 内存=%d bytes", m_test, recall_m * 100, t_m, idx_ivfpq.sa_encode(xb[:1]).nbytes * n_vectors // 1, ) # =================== 6. 不同 nbits(量化位数)对比 =================== logger.info("=== 6. 不同 nbits(量化位数)对比 ===") for nbits_test in [4, 8]: q = faiss.IndexFlatL2(dim) idx_ivfpq = faiss.IndexIVFPQ(q, dim, nlist, m, nbits_test) idx_ivfpq.train(xb) idx_ivfpq.add(xb) idx_ivfpq.nprobe = 10 t0 = time.perf_counter() _, indices_nb = idx_ivfpq.search(xq, top_k) t_nb = time.perf_counter() - t0 recall_nb = recall_at_k(indices_flat, indices_nb, top_k) logger.info( " nbits=%1d | 召回率@10=%.2f%% | 搜索耗时=%.4f s", nbits_test, recall_nb * 100, t_nb, ) if __name__ == "__main__": main()
DiskANN:磁盘ANN索引
字面意思,有点像Mysql的InnoDB
-
场景
- 数据量级非常大
- 内存无法下方到全部索引数据
- 仍然希望快速索引
-
特点
- 核心目标是减少随机磁盘访问
- 适合超大规模检索
- 更偏生产级大规模系统
-
示例
"""DiskANN-style Vamana 图索引(简化教学实现)。 纯 Python + NumPy 实现,演示 DiskANN 核心原理: 1. Vamana 图构建(随机初始化 + 贪婪搜索 + RobustPrune) 2. 贪婪搜索查询 3. 参数调优(R, L, alpha) 4. 召回率与速度对比 5. 保存 / 加载索引 """ from __future__ import annotations import logging import random import time from typing import Any import numpy as np logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) def recall_at_k(ground_truth: np.ndarray, approx_results: np.ndarray, k: int) -> float: """计算召回率:approx_results 中有多少命中 ground_truth 前 k 个。""" correct = 0 total = 0 for gt_row, app_row in zip(ground_truth, approx_results): gt_set = set(gt_row[:k]) app_set = set(app_row[:k]) correct += len(gt_set & app_set) total += k return correct / total class VamanaIndex: """简化版 Vamana 图索引(DiskANN 核心算法教学实现)。 参数: dim: 向量维度 R: 最大出度(每个节点的最大邻居数) L: 搜索列表大小(构建和搜索时的候选集大小) alpha: 鲁棒性修剪阈值(>1,越大图越稀疏) """ def __init__(self, dim: int, R: int = 16, L: int = 32, alpha: float = 1.2) -> None: self.dim = dim self.R = R self.L = L self.alpha = alpha self.vectors: np.ndarray | None = None self.graph: list[set[int]] = [] self.medoid: int = 0 def _euclidean_distance(self, x: np.ndarray, y: np.ndarray) -> float: """计算两个向量间的欧氏距离。""" return float(np.linalg.norm(x - y)) def _greedy_search( self, query: np.ndarray, k: int, start_node: int | None = None ) -> tuple[list[float], list[int]]: """贪婪搜索:从入口点开始,逐步走向查询向量。""" if self.vectors is None: raise RuntimeError("Index not built yet") entry = self.medoid if start_node is None else start_node # 候选集:已发现但未扩展的节点,按到 query 的距离排序 candidates: list[tuple[float, int]] = [ (self._euclidean_distance(self.vectors[entry], query), entry) ] visited: set[int] = {entry} results: list[tuple[float, int]] = [] while candidates: # 取出距离 query 最近的候选 dist, node = candidates.pop(0) results.append((dist, node)) # 如果当前结果集已超过 L,且最远的都比候选里最近还近,停止 if len(results) >= self.L: farthest_in_results = max(results[: self.L], key=lambda x: x[0]) if not candidates or farthest_in_results[0] < candidates[0][0]: break # 扩展邻居 for neighbor in self.graph[node]: if neighbor in visited: continue visited.add(neighbor) ndist = self._euclidean_distance(self.vectors[neighbor], query) # 插入排序到 candidates inserted = False for i, (cdist, _) in enumerate(candidates): if ndist < cdist: candidates.insert(i, (ndist, neighbor)) inserted = True break if not inserted: candidates.append((ndist, neighbor)) # 返回前 k 个 results.sort(key=lambda x: x[0]) distances = [d for d, _ in results[:k]] indices = [i for _, i in results[:k]] return distances, indices def _robust_prune(self, point_idx: int, candidate_pool: set[int]) -> set[int]: """鲁棒性修剪:从候选池中选择最多 R 个邻居,保证 alpha-可达性。""" if self.vectors is None: raise RuntimeError("Index not built yet") candidates = list(candidate_pool - {point_idx}) # 按到 point_idx 的距离排序 candidates.sort( key=lambda n: self._euclidean_distance( self.vectors[point_idx], self.vectors[n] ) ) new_neighbors: set[int] = set() for c in candidates: if len(new_neighbors) >= self.R: break # alpha-条件:如果存在已选邻居 p,使得 dist(c, p) < alpha * dist(point, c) # 则 c 可以通过 p 到达,不需要直接连接 point_dist = self._euclidean_distance( self.vectors[point_idx], self.vectors[c] ) dominated = False for p in new_neighbors: cross_dist = self._euclidean_distance(self.vectors[c], self.vectors[p]) if cross_dist < self.alpha * point_dist: dominated = True break if not dominated: new_neighbors.add(c) return new_neighbors def build(self, vectors: np.ndarray) -> None: """构建 Vamana 图索引。""" n = vectors.shape[0] self.vectors = vectors.astype("float32") logger.info( "构建 Vamana 图: n=%d, dim=%d, R=%d, L=%d", n, self.dim, self.R, self.L ) # 1. 找到 medoid(到所有其他点距离之和最小的点)作为搜索入口 logger.info("计算 medoid...") # 简化:用随机子集估计 medoid sample_size = min(n, 500) sample_indices = np.random.choice(n, sample_size, replace=False) sample = self.vectors[sample_indices] # 计算样本间距离矩阵 dists = np.linalg.norm( sample[:, np.newaxis, :] - sample[np.newaxis, :, :], axis=2 ) medoid_sample_idx = int(np.argmin(dists.sum(axis=1))) self.medoid = int(sample_indices[medoid_sample_idx]) logger.info("Medoid: %d", self.medoid) # 2. 初始化随机图(每个节点连接 R 个随机邻居) logger.info("初始化随机图...") self.graph = [] for i in range(n): neighbors = set() while len(neighbors) < min(self.R, n - 1): j = random.randint(0, n - 1) if j != i: neighbors.add(j) self.graph.append(neighbors) # 3. Vamana 优化:迭代改进图质量 logger.info("优化图结构(1 轮)...") permutation = list(range(n)) random.shuffle(permutation) for idx, i in enumerate(permutation): if idx % 1000 == 0 and idx > 0: logger.info(" 已处理 %d/%d", idx, n) # 贪婪搜索找到 L 个候选 query = self.vectors[i] _, candidates = self._greedy_search(query, self.L, start_node=self.medoid) candidate_pool = set(candidates) # 加入当前邻居 candidate_pool |= self.graph[i] # RobustPrune 重新选择邻居 new_neighbors = self._robust_prune(i, candidate_pool) self.graph[i] = new_neighbors # 双向添加边 for j in new_neighbors: self.graph[j].add(i) if len(self.graph[j]) > self.R: # 如果超出度数限制,对 j 也做修剪 self.graph[j] = self._robust_prune(j, self.graph[j] | {i}) logger.info("Vamana 图构建完成") def search(self, queries: np.ndarray, k: int) -> tuple[np.ndarray, np.ndarray]: """批量搜索。""" if self.vectors is None: raise RuntimeError("Index not built yet") nq = queries.shape[0] all_distances = np.zeros((nq, k), dtype="float32") all_indices = np.zeros((nq, k), dtype="int64") for i in range(nq): distances, indices = self._greedy_search(queries[i], k) # 如果结果不足 k,用 -1 和 inf 填充 while len(indices) < k: indices.append(-1) distances.append(float("inf")) all_distances[i] = distances[:k] all_indices[i] = indices[:k] return all_distances, all_indices def save(self, path: str) -> None: """保存索引到文件(NPZ 格式)。""" if self.vectors is None: raise RuntimeError("Index not built yet") # 将 set 转换为 list 以便序列化 graph_lists = [list(neighbors) for neighbors in self.graph] max_len = max(len(g) for g in graph_lists) # 填充到等长以便存为数组 graph_array = np.full((len(graph_lists), max_len), -1, dtype="int32") for i, g in enumerate(graph_lists): graph_array[i, : len(g)] = g np.savez( path, vectors=self.vectors, graph=graph_array, medoid=self.medoid, dim=self.dim, R=self.R, L=self.L, alpha=self.alpha, ) logger.info("索引已保存到 %s", path) def load(self, path: str) -> None: """从文件加载索引。""" data: Any = np.load(path) self.vectors = data["vectors"] self.dim = int(data["dim"]) self.R = int(data["R"]) self.L = int(data["L"]) self.alpha = float(data["alpha"]) self.medoid = int(data["medoid"]) # 将数组还原为 set 列表 graph_array = data["graph"] self.graph = [] for row in graph_array: neighbors = {int(x) for x in row if x >= 0} self.graph.append(neighbors) logger.info("索引已从 %s 加载,n=%d", path, len(self.graph)) def main() -> None: dim = 64 n_vectors = 5_000 n_queries = 100 top_k = 10 # 生成随机向量 logger.info("生成数据: %d 条向量, dim=%d", n_vectors, dim) xb = np.random.rand(n_vectors, dim).astype("float32") xq = np.random.rand(n_queries, dim).astype("float32") # =================== 1. 精确搜索(暴力 Flat L2)作为 ground truth =================== logger.info("=== 1. FlatL2(精确搜索,作为 Ground Truth) ===") flat_dists = np.linalg.norm(xb[:, np.newaxis, :] - xq[np.newaxis, :, :], axis=2) indices_flat = np.argsort(flat_dists, axis=0)[:top_k].T # 计算 FlatL2 耗时(模拟) t0 = time.perf_counter() for _ in range(5): _ = np.argsort( np.linalg.norm(xb[:, np.newaxis, :] - xq[np.newaxis, :, :], axis=2), axis=0, )[:top_k] flat_time = (time.perf_counter() - t0) / 5 logger.info("FlatL2 搜索耗时: %.4f s", flat_time) # =================== 2. Vamana 图索引 =================== logger.info("=== 2. Vamana 图索引(DiskANN 核心) ===") index = VamanaIndex(dim=dim, R=12, L=32, alpha=1.2) index.build(xb) t0 = time.perf_counter() distances_vamana, indices_vamana = index.search(xq, top_k) vamana_time = time.perf_counter() - t0 recall = recall_at_k(indices_flat, indices_vamana, top_k) logger.info( "Vamana 搜索耗时: %.4f s | 召回率@10=%.2f%% | 加速比=%.1fx", vamana_time, recall * 100, flat_time / vamana_time, ) # =================== 3. 参数调优:不同 L(搜索列表大小) =================== logger.info("=== 3. 不同 L(搜索列表大小)对比 ===") for L in [8, 16, 32, 64]: idx = VamanaIndex(dim=dim, R=12, L=L, alpha=1.2) idx.build(xb) t0 = time.perf_counter() _, indices_L = idx.search(xq, top_k) t_L = time.perf_counter() - t0 recall_L = recall_at_k(indices_flat, indices_L, top_k) logger.info( " L=%2d | 召回率@10=%.2f%% | 搜索耗时=%.4f s", L, recall_L * 100, t_L, ) # =================== 4. 参数调优:不同 R(最大出度) =================== logger.info("=== 4. 不同 R(最大出度)对比 ===") for R in [4, 8, 16, 24]: idx = VamanaIndex(dim=dim, R=R, L=32, alpha=1.2) idx.build(xb) t0 = time.perf_counter() _, indices_R = idx.search(xq, top_k) t_R = time.perf_counter() - t0 recall_R = recall_at_k(indices_flat, indices_R, top_k) logger.info( " R=%2d | 召回率@10=%.2f%% | 搜索耗时=%.4f s", R, recall_R * 100, t_R, ) # =================== 5. 参数调优:不同 alpha(修剪阈值) =================== logger.info("=== 5. 不同 alpha(修剪阈值)对比 ===") for alpha in [1.0, 1.2, 1.5, 2.0]: idx = VamanaIndex(dim=dim, R=12, L=32, alpha=alpha) idx.build(xb) t0 = time.perf_counter() _, indices_a = idx.search(xq, top_k) t_a = time.perf_counter() - t0 recall_a = recall_at_k(indices_flat, indices_a, top_k) logger.info( " alpha=%.1f | 召回率@10=%.2f%% | 搜索耗时=%.4f s", alpha, recall_a * 100, t_a, ) # =================== 6. 保存 / 加载索引 =================== logger.info("=== 6. 保存 / 加载 Vamana 索引 ===") index.save("/tmp/demo_vamana.index") loaded = VamanaIndex(dim=dim) loaded.load("/tmp/demo_vamana.index") logger.info("加载后总向量数: %d", loaded.vectors.shape[0]) _, indices_loaded = loaded.search(xq[:3], top_k) for i in range(3): logger.info(" Query %d:", i) for idx in indices_loaded[i]: logger.info(" idx=%d", idx) if __name__ == "__main__": main()
五、总结
现实业务中,可以根据以上索引的特点进行选择,大致可分为以下(从前面到后,准确性到数据规模):
- Flat:准确、最慢
- HNSW:高召回,低延迟
- IVF_FLAT:分桶检索
- IVF_PQ:分桶压缩
- DiskANN:磁盘ANN